Lexicon
Punnet
Fast2 versatility comes mainly from its pivot format called punnet.
This is a basic XML serialized punnet :
<?xml version='1.0' encoding='UTF-8'?>
<ns:punnet xmlns:ns="http://www.arondor.com/xml/document" punnetId="34c5434c-4234-4fa2-9f91-7882a899a994#1">
<ns:documentset>
<ns:document documentId="34c5434c-4234-4fa2-9f91-7882a899a994">
<ns:contentset>
<com.arondor.fast2p8.model.punnet.ContentContainer contentStorage="URL">
<ns:url>C:/samples/file.pdf</ns:url>
</com.arondor.fast2p8.model.punnet.ContentContainer>
</ns:contentset>
<ns:dataset>
<ns:data name="name" type="String">
<ns:value>sample</ns:value>
</ns:data>
</ns:dataset>
<ns:folderset>
<ns:folder parent-path="/primary-folder/subfolder" name="sample">
<ns:dataset />
</ns:folder>
</ns:folderset>
<ns:annotationset />
</ns:document>
</ns:documentset>
<ns:dataset />
<folderSet />
</ns:punnet>
In a more readable way, a punnet can be illustrated as follows :
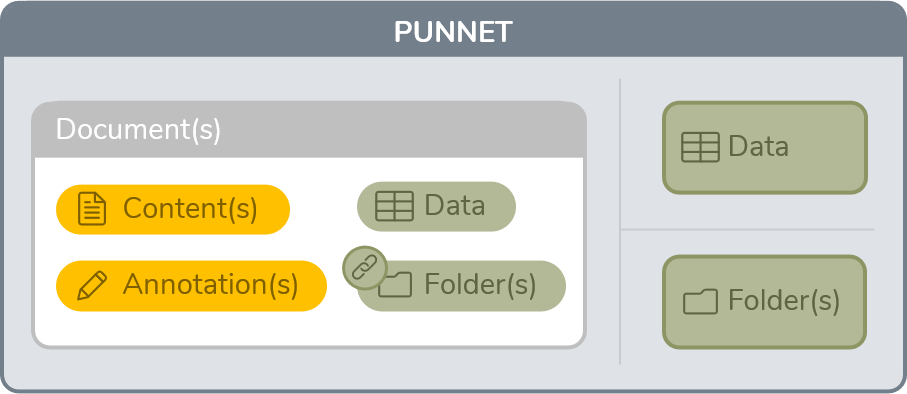
As you can see, each punnet contains few elements : data, folder and document. A document can also contains his own data, his content with annotations and the folder where he’s stored.
-
Data object represents metadata in the GED sense. It contains a name, a type, and one or more values
-
Content object materializes document content that can be simple or made up of several pages. It can be materialized by a relative or absolute path to its storage location or stored directly in memory / in an XML file
-
Annotation object represents an annotation (post-its, arrow…) affixed to the content of a document. This object is not conceptualized in all EDM systems.
-
Folder object represents a folder in the GED or file system sense, and can have metadata as well as links to documents
Task
Task can be represented as a processing unit to be applied to a punnet. A punnet comes at the entry of the task, as an input. The task performs operations and then outputs the modified punnet.
During the processing of each task, statistics are collected allowing to know the number of punnets processed per second. This is the actual throughput of the task and it is of course dependent on the environment (neighboring tasks, multi-thread…) From this speed, Fast2 tries to estimate the average time left for all the tasks.
One of the benefits of these statistics is the ability to visualize bottlenecks. Sometimes some tasks have a longer processing time than others. Thanks to the visualization of the queues, it is quite easy to know which task is greedy.
When multiple tasks are linked together it represents a processing chain or a workflow where each punnet will be processed task by task. We will call this object a campaign.
Campaign
As we have just seen, a campaign is made up of several tasks. In other words, it represents an instance of a map.
A campaign has a unique name
Despite this uniqueness, each campaign can be ran multiple times. The statistical data of the new run will be added to the previous run(s).
A new campaign must be “run as new”
Later you will have the possibility to add runs to this one.
A user has the opportunity to stop any campaign when he wants. He can always restart the campaign later.
For each campaign a retry feature is also available. This makes it possible to filter certain punnets and to replay them directly in the campaign. For instance, retry each punnet in exception. You can even select which type of exception you want.
Broker
This is the heart of the matter, say hello to the broker. Scheduling, orchestrating or even managing queues : the broker is everywhere.
His first job is to handle workers that we will see a little further down. Worker coordination is a key point in terms of performance, knowing that there may be a multitude of them.
In addition, the broker ensures the persistence and traceability of the data carried out by punnets into ElasticSearch. Logs, data and errors and other stuff are stored into ElasticSearch.
Worker
They are waiting in silence to do their job. When a punnet needs to be processed by a task, the broker informs workers that work has to be done. The workers represent the foundations and as their name suggests, do the tasks.
If the workload is too important, you can manually add workers to speed up processing.