
So you’ve finally decided to migrate your documents. Whatever the reason, it’s worth the effort. To avoid common mistakes you will need to follow a solid plan of action. As you might expect, each migration is unique and brings its own challenges : the source, the repository complexity and the transformations to be applied are a few examples among others. In spite of it all, we can find many similar steps between migrations. The goal of this article is to present the general structure of a mass documentary migration with its unmissable steps, and to highlight potential risks before even starting the project.
Analysis
The first step of analysis is understanding the source of the migration. Several criteria will have to be met in order to reckon the data source as precisely as possible. It all starts with the volume. You must know how many documents you have to migrate because it becomes a potential showstopper for the project once coupled to time constraints. POCs and other performance tests will help determine the average speed for a bulk of documents, and extrapolate to your whole data set.
The complexity of the documents is the next focus point. Identify how documents are related to each other, their mime type, their sensibility when it comes to confidential data, etc. But all this is directly linked to the diversity of your documents. List each metadata for each of them. Verify if they are all typed the same way. These elements will determine how the validation rules will be set. These rules will confirm the success state of the migration on the target system. They also can be coupled to business rules ー reworking data sets, transforming some metadata or dealing with the content of the document like an annotation. It will be necessary to involve the people concerned, the users working with the migrated documents on a daily basis and who will know what rules to apply. But keep in mind : the more rules you add, the more tricky it will be to monitor the migration.
The last part is about performance. For each known step (extraction, transformation, injection) you must be able to estimate the expected performances. It is likely that the window of action to perform the extraction will be brief since it often happens in a production environment. Base your estimations upon the minimum acceptable speed to deal with your constraints.

In addition, source and target environments must be studied to assimilate properly the amount of data. There are two scenarios : the first is when the client already has an ECM where the sources are coming from; the second one is when no document management system is used. Contrary to what we might think, the second scenario is the hardest one. The collect can become a critical aspect. This is due to ensuring compatibility between the two systems. The required metadata are not always the same and it is therefore necessary to rework the data set. But in both cases : is the environment used during the migration period ? If so, you must delimite a period of time where you can extract and inject your documents.
Extraction
At this point we have a good knowledge about the whole migration. Before anything else, the best advice we can give you will be to make a backup of your dataset. It is likely that errors will occur and this is more than normal considering all the factors to take into consideration. Once the backup is done, the next challenge is to plan the extraction. In other words, we must find a way to connect the ETL to the source environment. It could be a batch, an API-based connector or even direct database/storage connection. No matter how you want to do it, the essential is to know how you will retrieve the document with its content, annotations and metadata. We must ensure that all of these elements must be easily accessible to modify them if needed. And this is precisely what brings us to the next point.
Transformation
This step can either be extremely complicated or straightforward. It mostly depends on your requirements. Some just want to change their ECM while others want to seize the opportunity to rework their data set. You may wonder the point in working on the data, since they already are exploitable. There is always a way to improve, clearify and bring an added-value to your data set. People tend to collect too much data from different sources, often below the current interest threshold. Sometimes, it’s better to distinguish what is relevant from what is not. Because of this, transformation becomes a powerful tool to use with precaution. Be careful to take into account the processing time for each task, these transformations come with a cost. It also takes time to implement ー which is not easy to plan. In addition, each step could probably become bottlenecks that we will have to find and resolve. Most of the bottlenecks have the same cause :
- Overly complex process
- Slow hardware (hard drive speed) and CPU power
- Connectors to ECM (sessions interdependence)

Injection
The last but not least step of the migration, the load part. Two strategies emerge for this : full load vs. incremental load. Most of the time, the volume is the inducer of the final method to go for. Full load method will be easier but will only suit small migrations. However, no matter the solution you choose, ordering and versioning will be your next challenges. Depending on your workflow, documents might not be processed in the same order that they were received. The injection must be in the good order otherwise the data will be corrupted : this aspect goes hand in hand with versioning. An example of some questions to be answered :
- What happens when a duplicate is detected ?
- Is the first document updated and a new version created ?
Monitoring
Once the migration is done, you want to ensure that everything is going well. But as you might expect, there will be errors. All the interest of monitoring will be to detect errors as soon as possible, and their causes as well. This work of traceability is possible only through markers that you put in a data source at the beginning of the migration through validation rules. But this step can be much harder than it seems. The best option is to check every transformation you have operated during the process. The more aspects you check, the more you will be both precise and sure that everything has been correctly migrated. But once again, the more you have to do, the longer it will take. It’s all about the balance between quality and quantity.
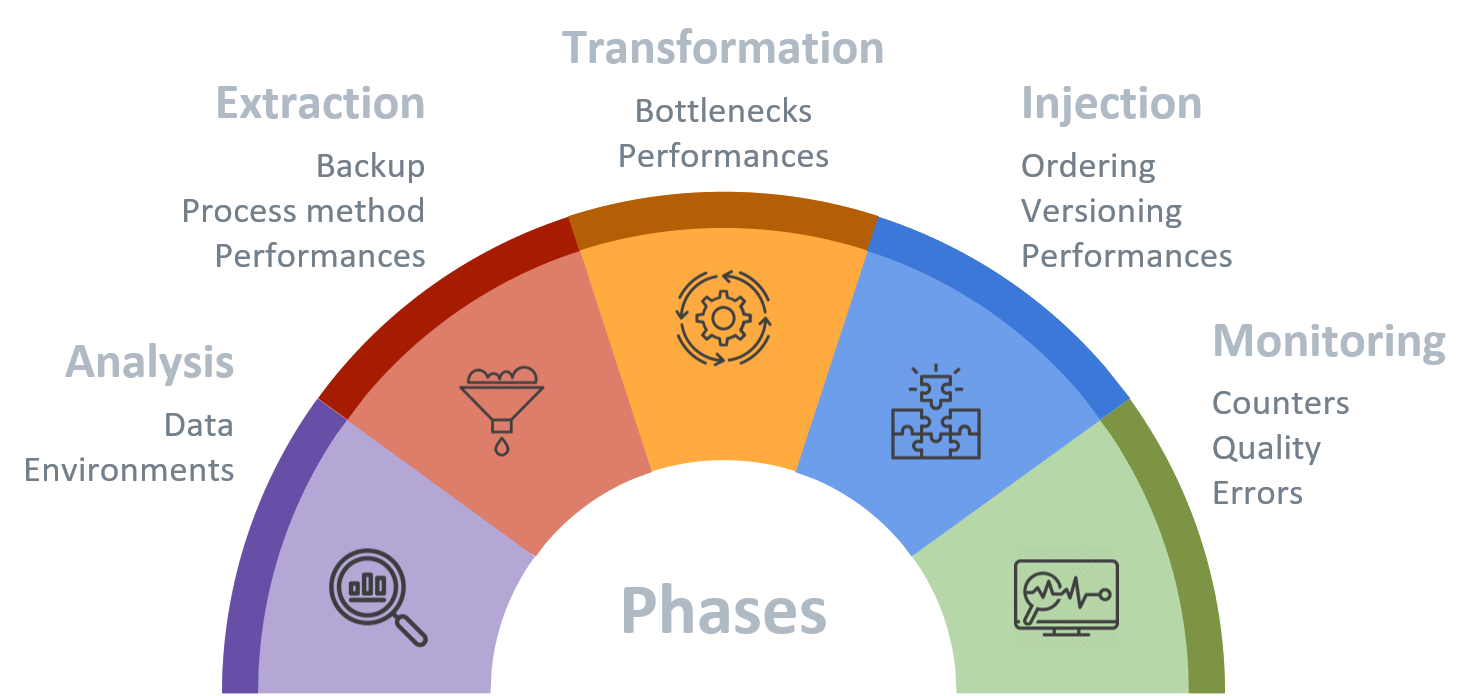
Everything we have just seen reveals the complexity behind a “simple” migration. We must not improvise and blindly push on. Be patient and examine everything you can to be sure of what you are doing. Even the smallest mistakes can have a big impact on the project. It only remains for me to wish you good luck for your next migrations.