
This project started during the middle of 2019 and lasted for about a year and a half. The topic was to migrate the whole document repository (seven million documents) of an insurance company, from a legacy homebrew ECM system to Alfresco 6. The target would be hosted and integrated by a company which owns an insurance contracts management solution. This solution had to communicate with Alfresco to let users access promptly their documents, thus not requiring to use an Alfresco user interface. We were responsible for the migration and set up of the environment.
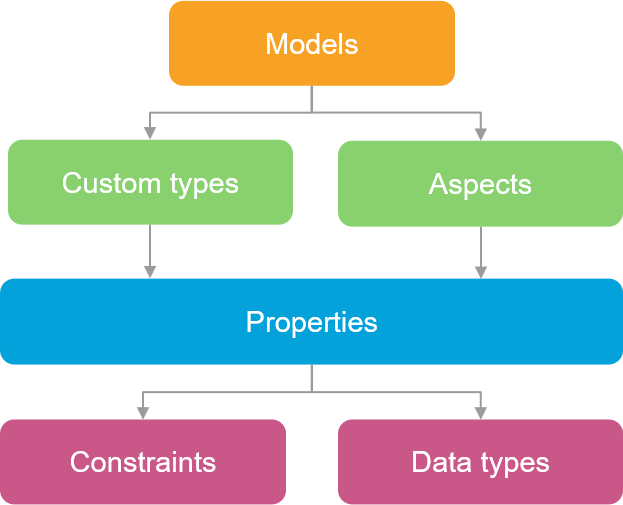
First things first, the Fast2 tech team had to prepare the Alfresco environment. User management and permissions have been settled in the data model. If you already know Alfresco, you are well aware that Alfresco uses a content model manager for custom models. These models define aspects which themselves defines the document properties. You can set the constraints to apply and the data type you expect through these elements. Once the target environment is ready for injection, we can move ahead for the migration.
The extraction was performed by the host company. As the source environment was still in production, it couldn’t be done in one go and therefore continued to be filled as migrations went on. Documents were delivered by packages through NASs to the company in charge of the migration because Fast2 was granted permission to directly access the source documents. This explains the matter of traceability and monitoring that had to be set for each run. We therefore had to check the input data, after transformations, injection etc. Extractions were provided by bulk with validation counters every time. Comparing those “extract” counters (registering what had been extracted from the NASs) to the “inject” one (registering what had been injected into Alfresco) created during migration, was the toughest part. It was made even more tricky since reworked batches were sometimes added to the extraction bulk. Each bundle came with its own behavior traceability specificities.
The content, a PDF or a TIFF, was linked to a CSV containing metadata. MD5 hashes of both formats were provided to assert data integrity. Transformations were classic : the content included annotations now and then. However there was a particular methodology to apply concerning the duplicate files : If the content was different, the version was incremented. Otherwise we focused on the properties; if they were not identical we only update the different properties without editing the document version. Finally, if both content and properties were identical, an error popped. The Fast2 standard Alfresco connector had evolved to satisfy this request.
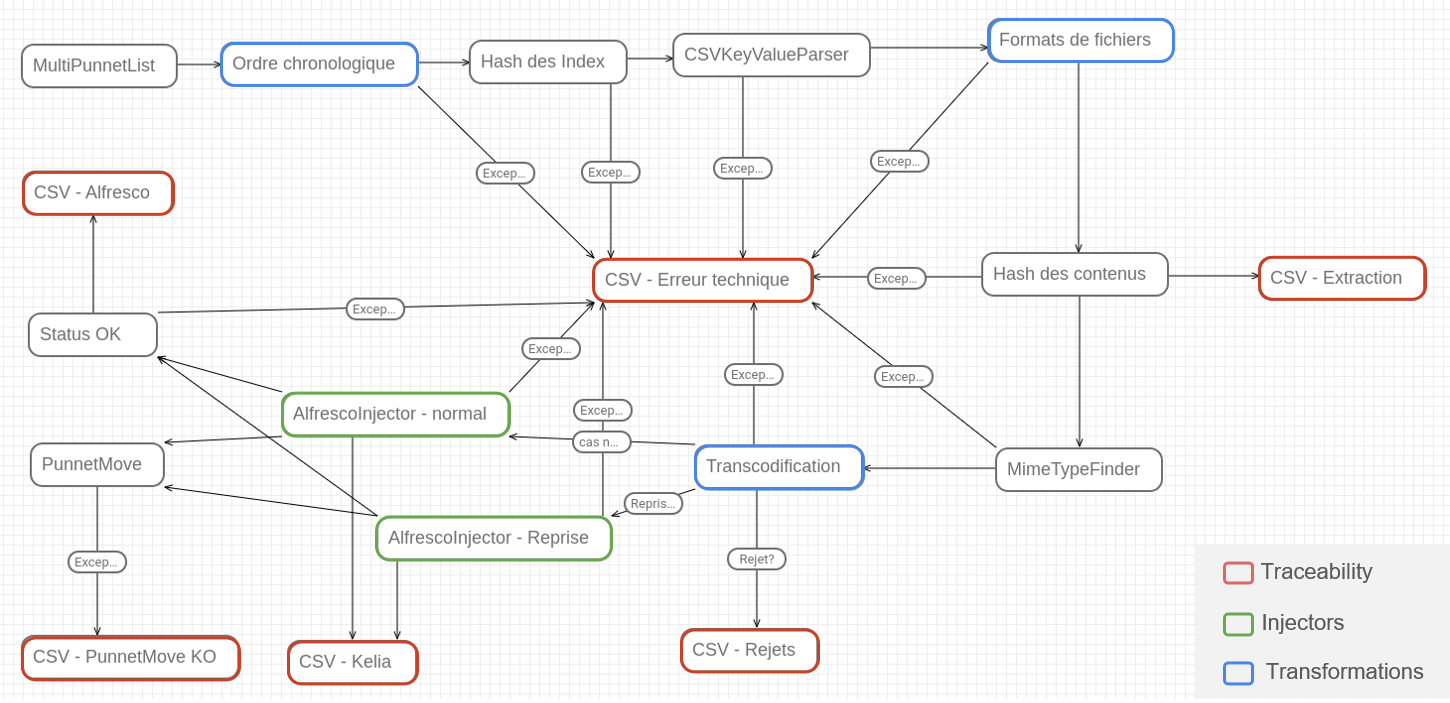
The picture above shows the workflow used for the migration process. The map started with verifying that all documents were coming in chronological order before any action. Transformations were performed after validating with the MD5 signature and controlling the files required metadata : mimeType and a list of mandatory properties. The map also presents a large number of CSV tasks whose purpose was to create reports and to handle errors all the migration along. These reports were used as a basis for the counters creation. After combining the reports, they were injected into our ElasticSearch instance to then be analyzed with Kibana. From this, we were able to create tables, graphics and build complete reports for monitoring as shown below.
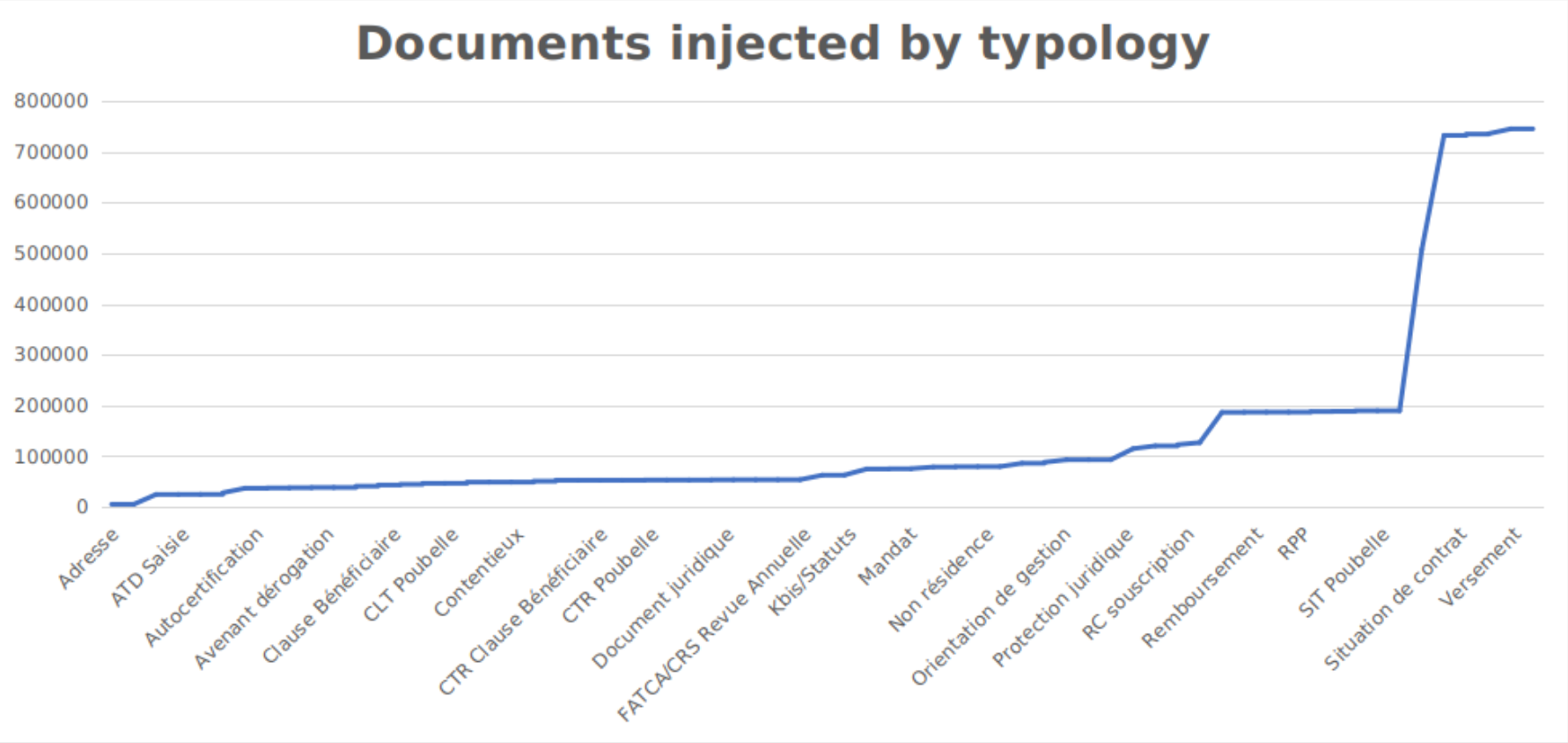
The picture above is the concatenation of all injected documents grouped by typology. Low level analytics can even be performed, till focusing on individual documents. The below picture shows one of these tables where documents are counted individually. We can see the number of annotations for each batch filtered by status.
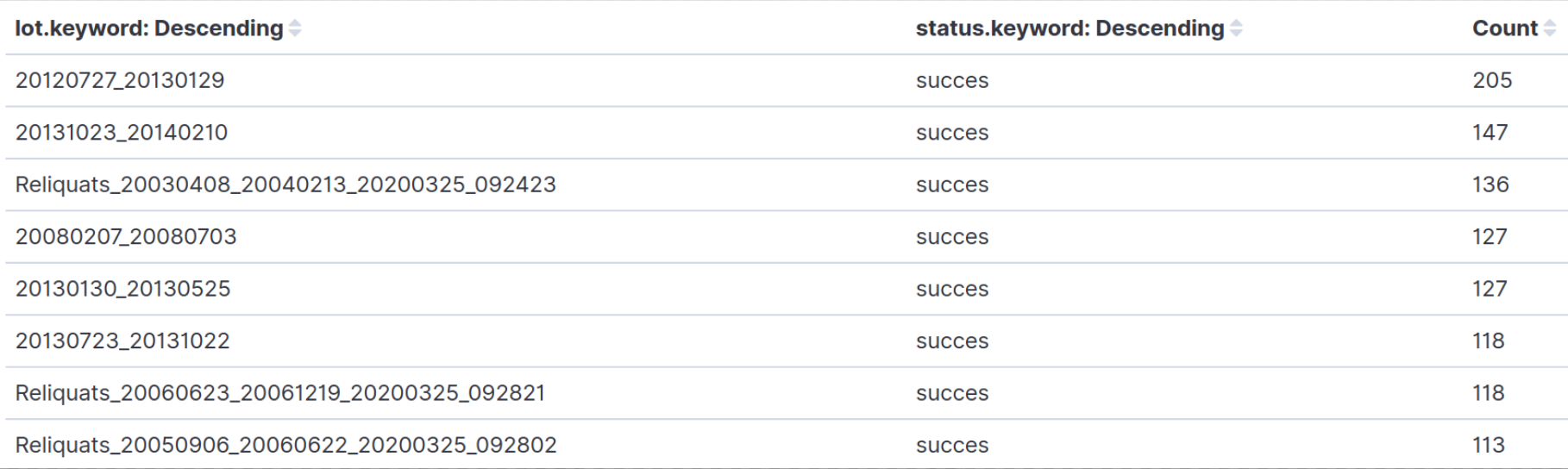
Of course, there were a lot of different counters based on versions, status (ok/errors/rejected), typology, comments, annotations, format, product code, etc.
Feedback
This project was a huge change for the final customer. It was the first time ever they went through such a massive operation. Needless to say, some things did not go as planned nor on time. Between the three companies involved, it took time to get organized. New people often landed on the project while others stepped back. Newcomers had to level up quickly to continue the work efficiently. Difficulty was increased due to the various aspects the project was related to : migration, dematerialization etc. The major stake was to successfully manage all the three parties while putting emphasis on the overall communication. The technicalities were far from highly demanding. The only complex job concerned the follow-up of the migration. There were a lot of indicators and counters to cross-reference in order to make sure everything was evolving as expected.
The POC span and the dry-runs were the most tedious. The POC helped us check the smooth running of the stages of the map and the real interest of data transformations, based on a representative sample of the whole migration. The dry-runs allowed us to estimate the time needed to complete the migration by taking a large enough sample. The organizational issues encountered by the integrator team have slowed down the project and were soon noticed by the final customer. Technical problems raised on Alfresco and ARender (the universal viewer proposed by Arondor) with some sort of snowball effect. The end customer got quite stressed, having no clue where he was going to end up. To prevent the project from being jeopardized, many meetings have been set up to better collaborate between Arondor and the integrator company, reassuring the end customer. Before continuing, better communication rules have been put in place between the three parties. This was possible thanks to the arrival of new people specifically dedicated to the management.
This project is a good example of how important project management is. Things can only go two ways : either you plan everything as early as possible, or you concede to iterate over each problem you encounter. Paying special attention to log management and environment could have made things a lot easier. As final advice, don’t undervalue devoting some time to training. It may sound like a waste of time, but it can bring much more than you imagine. Even though more people will get involved in the project, this approach will lower turnover rates, which is always a tricky thing to deal with. It will all end up as a success. You will complete the objectives.